If you’re still defaulting to Claude Opus in GitHub Copilot, you’re probably burning quota for very little in return.
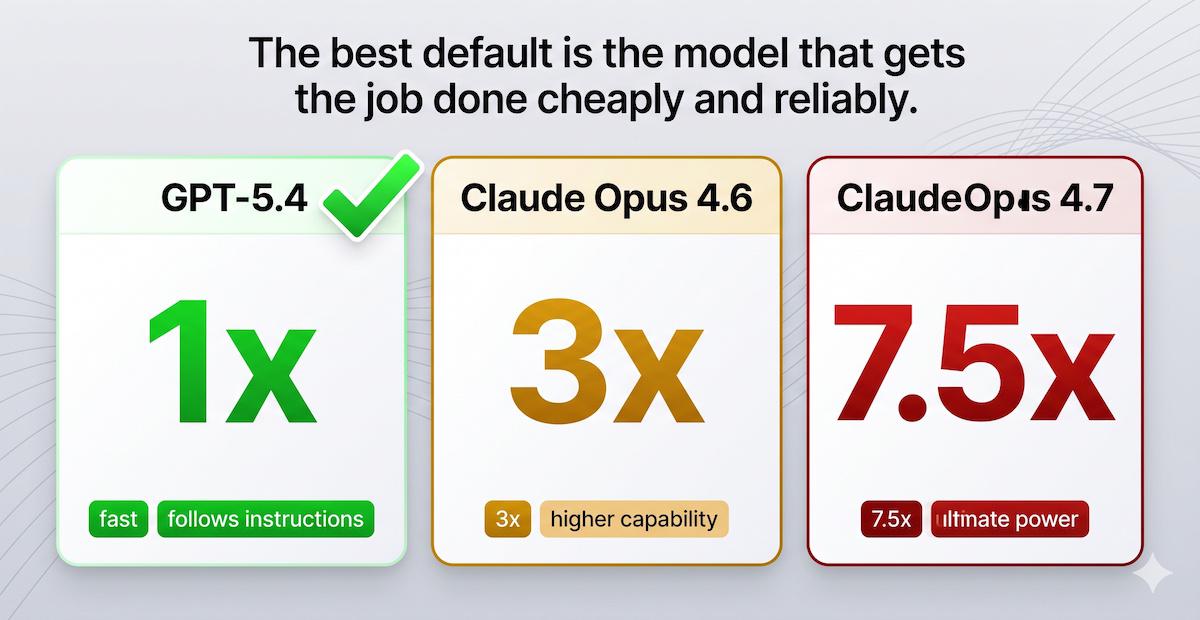
As of April 2026, Claude Opus 4.6 costs 3x requests and Claude Opus 4.7 costs 7.5x. Meanwhile GPT-5.4 is still 1x, even if you push reasoning effort all the way up to xhigh in VS Code. That cost gap is enormous, and I don’t see anything close to an equivalent jump in quality.
The economics are not even close#
Here is the decision in its simplest form:
| Model | Premium request multiplier | What I get from it |
|---|---|---|
| GPT-5.4 | 1x | Strong instruction-following, fast enough, good enough for most serious coding work |
| Claude Opus 4.6 | 3x | Different behaviour, but nowhere near 3x more useful |
| Claude Opus 4.7 | 7.5x | An even bigger bill, still without a remotely proportional gain |
If Opus were giving me 3x or 7.5x better output, fine. Pay the premium. But that is not what I see in day-to-day coding. The quality is generally comparable, and in quite a few cases I actually prefer GPT-5.4.
That matters because the same quota now buys you either one expensive Opus session, or three to seven-and-a-half GPT-5.4 sessions. For real engineering work, I know which side of that trade I want.
Opus autonomy is not the win people think it is#
Opus is more autonomous. Give it a vague brief and it will keep going, infer intent, and try to rescue the task.
That can look impressive. It can also be exactly how an agent goes off into the weeds.
For a well-structured coding workflow, I do not want the model freelancing. I want to plan first, define the constraints, and then have the model follow the brief tightly. GPT-5.4 is better at that. It is more literal in a good way, which means the same general quality level is easier to reproduce on demand.
If you want premium sessions to go further, the real optimisation is the workflow, not the most expensive model. I already wrote about that in Choosing the right GitHub Copilot model for the job and Stop wasting premium requests in GitHub Copilot: the ask tool trick nobody talks about.
If you genuinely prefer Opus for a niche task, fine. Just make it the exception, not the default.
Speed and availability matter more than people admit#
GPT-5.4 is generally faster, and it also seems to hit rate limits less often. That matters a lot.
People underestimate what latency does to the workflow. A slower model gives you fewer iterations, slower feedback, and more friction every time you want to adjust course. Even if benchmark quality were slightly higher, which I do not think is obvious here, the overall workflow can still be worse.
My default is easy:
- GPT-5.4 at 1x
- xhigh reasoning when I need deeper thinking
- a proper plan first, before I let an agent start changing code
That combination is cheaper, faster, and more reliable for the kind of structured coding work I actually want to do.
The bigger lesson#
The future of successful models is not going to belong only to the one that wins by a tiny margin on a benchmark.
The winners will be the models that are good enough to do real work, reliable enough to follow instructions, and cheap enough to use constantly without thinking twice.
Right now, GPT-5.4 looks a lot closer to that future than Claude Opus does in GitHub Copilot.
Give it a proper try. I doubt you’ll miss the 7.5x bill.
Happy prompting!